
CD_HIEFNet: Cloud Detection Network Using Haze Optimized Transformation Index and Edge Feature for Optical Remote Sensing Imagery



Abstract
:
1. Introduction
- We used the HOT index image and the multispectral (MS) image together as the input of the network, which added the spectral characteristics of the clouds and enabled the network to distinguish difficult regions that are easily confused with clouds, so that the network could distinguish regions that are easily confused with clouds;
- We deployed an edge feature detection (EFE) module to enhance the extraction of cloud boundary details in the network. This made the network fit the cloud boundary well and allowed it to detect various cloud types;
- In our structure, we adopted ConvNeXt [40] as the backbone network. In the decoder stage, we used a structure to fuse shallow and deep features from bottom to top to compensate for the loss of edge and local information, which made it possible to recover boundary information effectively and obtain accurate results;
- CD_HIEFNet has great cloud detection performance for Landsat-8 (L8) Biome datasets. Moreover, the extended experiments showed that CD_HIEFNet had good generalization performance, which is important in practical applications.
2. Methodology
2.1. Backbone Network
2.2. HOT Index Extraction
2.3. Edge Feature Extraction Module
2.4. Focal Loss
3. Results and Discussion
3.1. Dataset Processing
3.1.1. Datasets
- The L8 Biome dataset: This dataset includes 96 L8 images sampled from all over the world with sizes of 8000 × 8000 (30 m resolution) and manually generated cloud masks. The dataset has eight types of scene—urban, forest, shrubland, grass, snow, barren, wetlands and water—and each scene type contains 12 images. In order to ensure data heterogeneity and diversity, images are selected with different paths/rows and cloud patterns;
- The SPARCS dataset: This consists of 80 sub-images of L8 images, and the size is 1000 × 1000 (30 m resolution). The purpose of the dataset was to select 12 additional scenarios to use in evaluating the classifier and to reduce the risk of overfitting. Therefore, it was used as the extended experimental data in this study;
- GF-1 data: The GF-1 satellite is equipped with a panchromatic/multispectral (PMS) camera. The PMS camera can acquire panchromatic images with a resolution of 2 m and MS images with a resolution of 8 m (four bands—blue, green, red and near-infrared), with sizes of approximately 5000 × 5000. The spectral range and the spatial resolution of GF-1 are different from those of L8. Therefore, we also used the MS images as extended experimental data to further verify the scalability of the network.
3.1.2. Pre-Processing
3.2. Experiment Settings
3.2.1. Implementation Details
| Algorithm 1. Cloud detection model training and verification |
| Input: are the data for model training, validation and testing, respectively; and are the images for the extended experiment; is the number of iterations; is the maximum number of iterations; is the initial network. |
| Output: model prediction results: ; model: ; evaluation index: . |
| 1: while < do |
| 2: |
| 3: update net parameters |
| 4: if % 200 == 0 then |
| 5: evaluate |
| 6: save the |
| 7: end if |
| 8: end while |
| 9: choose the best model in by |
| 10: predict |
| 11: compare with |
| 12: perform cloud detection for and |
3.2.2. Evaluation Metrics
3.3. Ablation Experiments
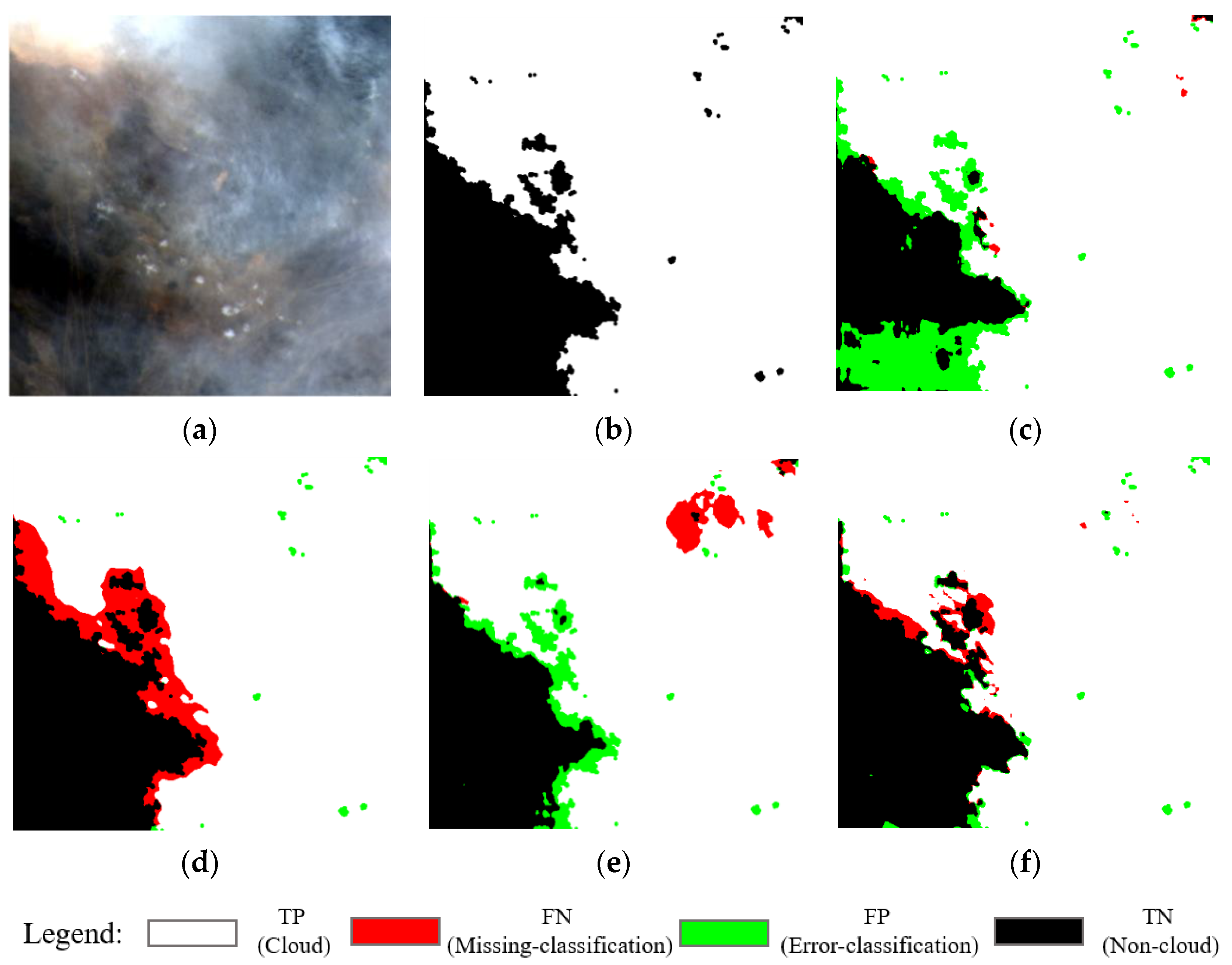
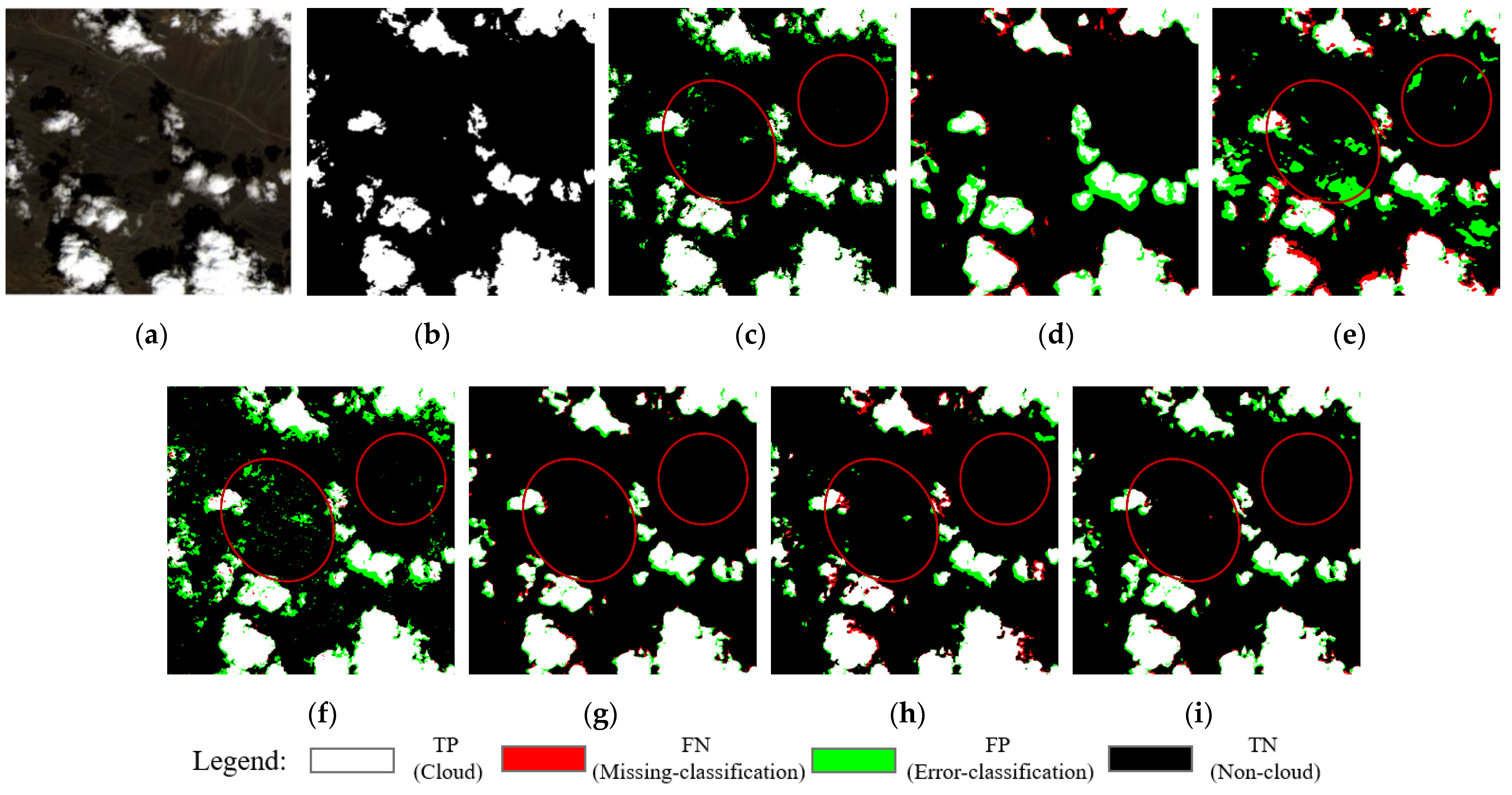
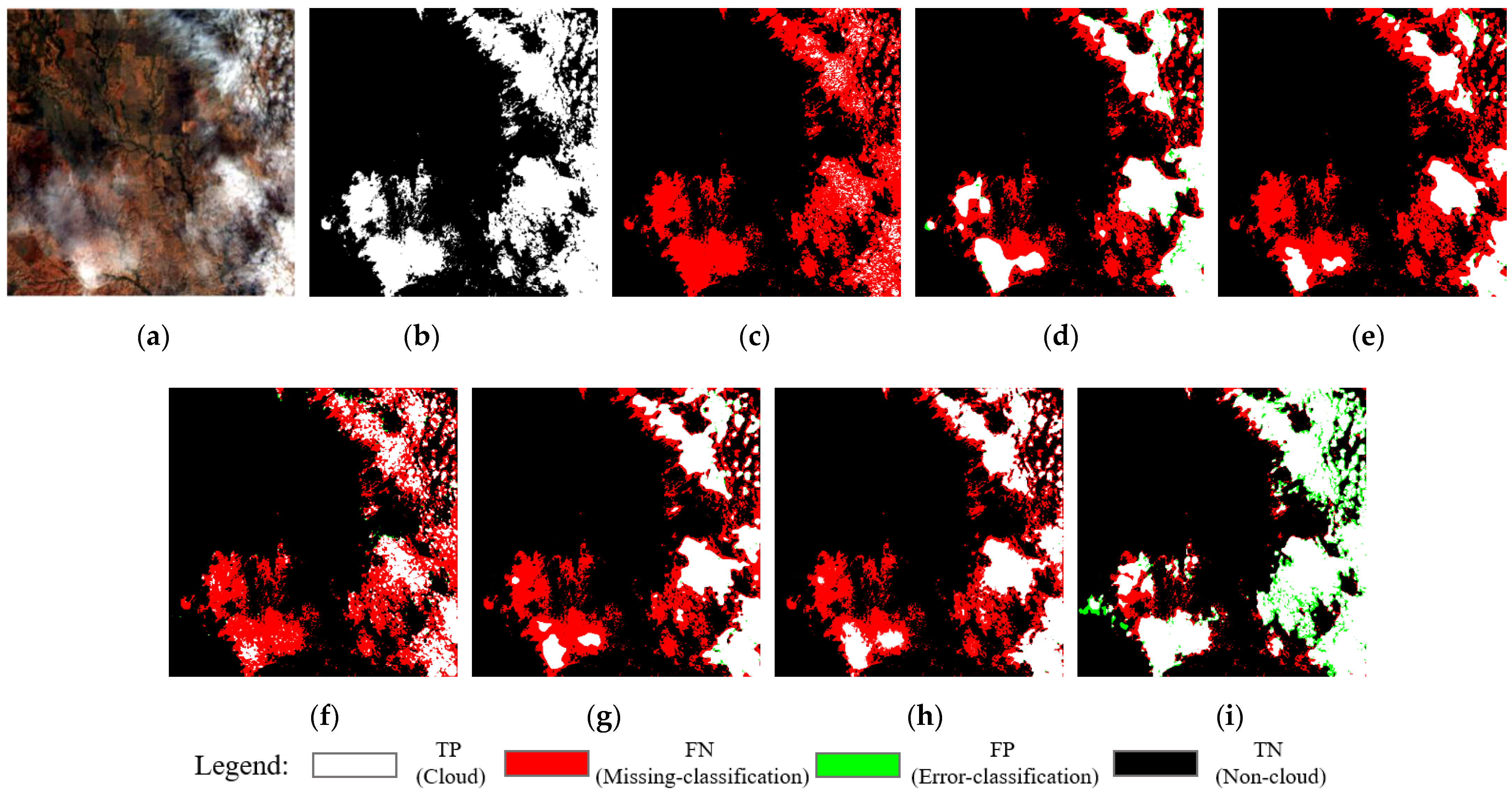
- Effectiveness of the HOT index: Spectral feature information is helpful in extracting clouds. In Table 2, it can be seen that, compared with the network without the HOT index, most of the evaluation indicators for the network with the HOT index were improved. The greatly improved PR shows that the addition of the HOT index spectral feature information was indeed beneficial for cloud detection. In Figure 5a–c, we can also see that the addition of the HOT index added the spectral feature information of the cloud to the network, which made it possible to effectively eliminate some confusing non-cloud pixels around thin clouds to improve accuracy;
- Effectiveness of the EFE module: Edge information plays a critical role in cloud detection. In Table 2, it is can be seen that the performance improvement resulting from the EFE module was much greater than that of the HOT index. The EFE module increased the OA value from 95.52% to 96.28%, the PR from 93.87% to 95.54%, the RR from 94.76% to 95.08%, the F1 score from 94.31% to 95.55% and the mIOU from 91.06% to 92.53%. In Figure 5c, it can be seen that the addition of the EFE module made the detection results more accurate, and the boundary fitting of the cloud was also strengthened. However, there were some pixels that were mistaken for non-cloud areas due to weak boundaries between thick and thin clouds;
- Effectiveness of the fusion of the HOT index and the EFE module: As shown in Table 2, the best performance for the network resulted from the fusion of the HOT index and the EFE modules, with which the OA increased by 1.0%, the PR increased by 1.7%, the RR increased by 0.8%, the F1 score increased by 1.2% and the mIOU increased by 1.8%. It can be seen in Figure 5f that the models that fused the two modules exhibited more accurate cloud detection results and finer edges. Only adding the EFE module caused a weak boundary error (see Figure 5e), but the spectral feature information added by the HOT index alleviated this situation. Moreover, the edge information extracted by the EFE module enabled some pixels with similar spectral features to be distinguished and the performance improved.
3.4. Comparative Experiments
3.5. Extended Experiments
3.5.1. Experiments in the SPARCS Dataset
3.5.2. Experiments with GF-1 Images
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, P.; Di, L.; Du, Q.; Wang, L. Remote sensing big data: Theory, methods and applications. Remote Sens. 2018, 10, 711. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Wang, G.; Zhang, D.; Xu, Y. Research on the application of remote sensing big data in urban and rural planning. Urb. Arch. 2020, 17, 30–31. [Google Scholar] [CrossRef]
- Yiğit, İ.O. Overview of big data applications in remote sensing. In Proceedings of the 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Louw, A.S.; Fu, J.; Raut, A.; Zulhilmi, A.; Yao, S.; McAlinn, M.; Fujikawa, A.; Siddique, M.T.; Wang, X.; Yu, X.; et al. The role of remote sensing during a global disaster: COVID-19 pandemic as case study. Remote Sens. Appl. Soc. Environ. 2022, 27, 100789. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Liu, P.; Zhao, L.; Wang, G.; Zhang, W.; Liu, J. Air quality predictions with a semi-supervised bidirectional LSTM neural network. Atmos. Pollut. Res. 2021, 12, 328–339. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Zhang, Y.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. 2004, 109. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Fernandez-Moran, R.; Gómez-Chova, L.; Alonso, L.; Mateo-García, G.; López-Puigdollers, D. Towards a novel approach for Sentinel-3 synergistic OLCI/SLSTR cloud and cloud shadow detection based on stereo cloud-top height estimation. ISPRS J. Photogramm. Remote Sens. 2021, 181, 238–253. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, G.; Gong, K.; Wei, M.; Gong, G. Research progress of cloud measurement methods. Meteorol. Sci. Technol. 2012, 40, 689–697. [Google Scholar] [CrossRef]
- Wei, L.; Shang, H.; Hu, S.; Ma, R.; Hu, D.; Chao, K.; Si, F.; Shi, J. Research on cloud detection method of GF-5 DPC data. J. Remote Sens. 2021, 25, 2053–2066. [Google Scholar] [CrossRef]
- Kanu, S.; Khoja, R.; Lal, S.; Raghavendra, B.S.; CS, A. CloudX-net: A robust encoder-decoder architecture for cloud detection from satellite remote sensing images. Remote Sens. Appl. Soc. Environ. 2020, 20, 100417. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Y. Research progress on cloud detection methods in remote sensing images. Remote Sens. Land Resour. 2017, 29, 6–12. [Google Scholar] [CrossRef]
- Singh, P.; Komodakis, N. Cloud-Gan: Cloud removal for Sentinel-2 imagery using a cyclic consistent generative adversarial networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1772–1775. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Cheng, Q.; Wu, P.; Gan, W.; Fang, L. Cloud removal in remote sensing images using nonnegative matrix factorization and error correction. ISPRS J. Photogramm. Remote Sens. 2019, 148, 103–113. [Google Scholar] [CrossRef]
- Hou, S.; Sun, W.; Zheng, X. A survey of cloud detection methods in remote sensing images. Space Electron. Technol. 2014, 11, 68–76. [Google Scholar] [CrossRef]
- Zhang, J. Research on Remote Sensing Image Cloud Detection Method Based on Deep Learning. Master’s Thesis, University of Chinese Academy of Sciences, Beijing, China, 2020. [Google Scholar] [CrossRef]
- Segal-Rozenhaimer, M.; Li, A.; Das, K.; Chirayath, V. Cloud detection algorithm for multi-modal satellite imagery using convolutional neural-networks (CNN). Remote Sens. Environ. 2020, 237, 111446. [Google Scholar] [CrossRef]
- Jedlovec, G. Automated detection of clouds in satellite imagery. In Advances in Geoscience and Remote Sensing; IntechOpen: London, UK, 2009. [Google Scholar] [CrossRef] [Green Version]
- Irish, R.R.; Barker, J.L.; Goward, S.N.; Arvidson, T. Characterization of the Landsat-7 ETM+ automated cloud-cover assessment (ACCA) algorithm. Photogramm. Eng. Remote Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Qin, Y.; Fu, Z.; Zhou, F.; Chen, Y. A method for automatic cloud detection using TM images. Geomat. Inf. Sci. Wuhan Univ. 2014, 39, 234–238. [Google Scholar] [CrossRef]
- Wang, Q.; Sun, L.; Wei, J.; Zhou, X.; Chen, T.; Shu, M. Improvement of dynamic threshold cloud detection algorithm and its application on high-resolution satellites. Acta Opt. Sin. 2018, 38, 376–385. [Google Scholar] [CrossRef]
- Kittler, J.; Pairman, D. Contextual pattern recognition applied to cloud detection and identification. IEEE Trans. Geosci. Remote Sens. 2007, GE-23, 855–863. [Google Scholar] [CrossRef]
- Cao, Q.; Zheng, H.; Li, X. A method for cloud detection in satellite remote sensing images based on texture features. Acta Aeronaut. Astronaut. Sin. 2007, 28, 661–666. [Google Scholar]
- Wang, K.; Zhang, R.; Yin, D.; Zhang, H. Remote sensing image cloud detection based on edge features and AdaBoost classification. Remote Sens. Technol. Appl. 2013, 28, 263–268. [Google Scholar] [CrossRef]
- Wang, W.; Song, W.; Liu, S.; Zhang, Y.; Zheng, H.; Tian, W. MODIS cloud detection algorithm combining Kmeans clustering and multispectral thresholding. Spectrosc. Spect. Anal. 2011, 31, 1061–1064. [Google Scholar] [CrossRef]
- Liou, R.J.; Azimi-Sadjadi, M.R.; Reinke, D.L.; Vonder-Haar, T.H.; Eis, K.E. Detection and classification of cloud data from geostationary satellite using artificial neural networks. In Proceedings of the IEEE World Congress on IEEE International Conference on Neural Networks, Orlando, FL, USA, 28 June–2 July 1994; pp. 4327–4332. [Google Scholar] [CrossRef]
- Latry, C.; Panem, C.; Dejean, P. Cloud detection with SVM technique. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 448–451. [Google Scholar] [CrossRef]
- Fu, H.; Feng, J.; Li, J.; Liu, J. FY-2G cloud detection method based on random forest. Bull. Surv. Map 2019, 3, 61–66. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. Cloud detection algorithm for remote sensing images using fully convolutional neural networks. In Proceedings of the IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Wang, Y.; Zhu, Y.; Ji, X.; Xing, T.; Li, W.; Zomaya, A.Y. P_SegNet and NP_SegNet: New neural network architectures for cloud recognition of remote sensing images. IEEE Access 2019, 7, 87323–87333. [Google Scholar] [CrossRef]
- Peng, L.; Liu, L.; Chen, X.; Chen, J.; Cao, X.; Qiu, Y. Research on generalization performance of remote sensing image cloud detection network: Taking DeepLabv3+ as an example. J. Remote Sens. 2021, 25, 1169–1186. [Google Scholar] [CrossRef]
- Zhan, Y.; Wang, J.; Shi, J.; Cheng, G.; Yao, L.; Sun, W. Distinguishing Cloud and Snow in Satellite Images via Deep Convolutional Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1785–1789. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An End-To-End Cloud Detection Algorithm for Landsat 8 Imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1029–1032. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhou, Q.; Wang, H.; Wang, Y.; Li, Y. Cloud Detection Using Gabor Filters and Attention-Based Convolutional Neural Network for Remote Sensing Images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2256–2259. [Google Scholar] [CrossRef]
- Guo, H.; Bai, H.; Qin, W. ClouDet: A dilated separable CNN-Based cloud detection framework for remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9743–9755. [Google Scholar] [CrossRef]
- Su, H.; Peng, Y.; Xu, C.; Feng, A.; Liu, T. Using improved DeepLabv3+ network integrated with normalized difference water index to extract water bodies in Sentinel-2A urban remote sensing images. J. Appl. Remote Sens. 2021, 15, 018504. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar] [CrossRef] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows C. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Zhang, Y.; Guindon, B.; Cihlar, J. An image transform to characterize and compensate for spatial variations in thin cloud contamination of Landsat images. Remote Sens. Environ. 2002, 82, 173–187. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bishop, M.C. Linear Models for Classification. In Pattern Recognition and Machine Learning (Information Science and Statistics); Jordan, M., Kleinberg, J., Scholkopf, B., Eds.; Springer: New York, NY, USA, 2006; p. 209. [Google Scholar]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D., Jr.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Proc. Syst. Proc. 2019, 32, 8026–8037. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Input | Output | Operator | Dilation Rate |
|---|---|---|---|---|
| 1 | 512 × 512 Cin | 128 × 128 × 96 | Conv 4 × 4, stride 4 LN ConvNeXt block × 3 | 1 |
| 2 | 128 × 128 × 96 | 64 × 64 × 192 | Downsample ConvNeXt block × 3 | 1 |
| 3 | 64 × 64 × 192 | 32 × 32 × 384 | Downsample ConvNeXt block × 9 | 1 |
| 4 | 32 × 32 × 384 | 32 × 32 × 768 | LN Conv 3 × 3, stride 1 ConvNeXt block × 3 | 2 |
| Method | OA | PR | RR | F1 Score | mIOU |
|---|---|---|---|---|---|
| ConvNeXt | 95.52% | 93.87% | 94.76% | 94.31% | 91.06% |
| ConvNeXt + HOT index | 95.78% | 94.47% | 94.84% | 94.66% | 91.55% |
| ConvNeXt + EFE | 96.28% | 95.54% | 95.08% | 95.31% | 92.53% |
| ConvNeXt + HOT index + EFE | 96.47% | 95.59% | 95.51% | 95.55% | 92.90% |
| Method | OA | PR | RR | F1 Score | mIOU |
|---|---|---|---|---|---|
| Fmask | 88.75% | 88.03% | 84.27% | 86.11% | 79.16% |
| FCN8s | 95.56% | 94.58% | 94.22% | 94.40% | 91.14% |
| U-Net | 93.03% | 89.14% | 92.98% | 91.02% | 86.38% |
| SegNet | 93.13% | 90.65% | 91.90% | 91.27% | 86.61% |
| DeepLabv3+ | 95.55% | 95.39% | 93.51% | 94.44% | 91.12% |
| CloudNet | 94.72% | 92.98% | 93.64% | 93.31% | 89.55% |
| CD_HIEFNet | 96.47% | 95.59% | 95.51% | 95.55% | 92.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Tong, L.; Yao, X.; Wu, Y.; Wan, G. CD_HIEFNet: Cloud Detection Network Using Haze Optimized Transformation Index and Edge Feature for Optical Remote Sensing Imagery. Remote Sens. 2022, 14, 3701. https://doi.org/10.3390/rs14153701
Guo Q, Tong L, Yao X, Wu Y, Wan G. CD_HIEFNet: Cloud Detection Network Using Haze Optimized Transformation Index and Edge Feature for Optical Remote Sensing Imagery. Remote Sensing. 2022; 14(15):3701. https://doi.org/10.3390/rs14153701
Chicago/Turabian StyleGuo, Qing, Lianzi Tong, Xudong Yao, Yewei Wu, and Guangtong Wan. 2022. "CD_HIEFNet: Cloud Detection Network Using Haze Optimized Transformation Index and Edge Feature for Optical Remote Sensing Imagery" Remote Sensing 14, no. 15: 3701. https://doi.org/10.3390/rs14153701